FMEでは、HTTP プロトコルによる API が公開されているウェブサービスには、一般に HTTPCaller トランスフォーマーによって接続することができ、また、XML, JSON, CSV 形式のデータは自在に変換できます。
ここでは、統計ダッシュボードAPIによるデータ取得の実験として、[時間] 2010~2015年の年別・[地域] 都道府県別の [系列] 人口総数をXML形式で取得し、PostgreSQL データベース (次の2テーブル) に格納するワークスペース例を掲げます。
出力先データベーステーブル
| テーブル名 | 列名 | 内容 |
|---|---|---|
| population | region_code | 地域コード |
| year | 年 | |
| population | 人口総数 | |
| region | code | 地域コード |
| name | 地域名称 (都道府県名) |
統計ダッシュボードAPIの利用規約、技術的な仕様 (リクエストURL・パラメーター、レスポンスのスキーマ等) については、統計ダッシュボードサイトのAPI関連ページを参照してください。
FME 2017.0.1.1 build 17291
FMEワークスペース例

HTTPCaller: Creator から出力されたフィーチャーを受け取ったタイミングで、次のパラメーター設定に基づいて2010~2015年の年別・都道府県別の人口総数データをXML形式で取得するためのHTTPリクエスト (GETメソッド) を発行し、レスポンスとして得られたXML文書を属性として持ったフィーチャーを出力します。
HTTPCaller の主要パラメーター
Request:
Request URL: http://data.e-stat.go.jp/dashboard/api/1.0/Xml/getData
HTTP Method: GET
Query String Parameters:
これらの API パラメーターの全部または一部を、通常の REST API パラメーターの書式で Request URL 文字列に含めても構いません。
Response:
Response Body Attribute: _response_body
Request URL: http://data.e-stat.go.jp/dashboard/api/1.0/Xml/getData
HTTP Method: GET
Query String Parameters:
| Name | Value | 備考 |
| Lang | JP | 取得するデータの言語 (JP:日本語) |
| MetaGetFlg | Y | メタ情報取得有無のフラグ (Y:取得する) |
| IndicatorCode | 0201010000000010000 | 系列コード |
| RegionLevel | 3 | 地域レベル (3:都道府県) |
| TimeFrom | 2010CY00 | 時間軸 (開始) |
| TimeTo | 2015CY00 | 時間軸 (終了) |
Response:
Response Body Attribute: _response_body
XMLFragmenter: XML文書から全ての VALUE 要素をXML断片として抽出するともに、それらを平坦化して regionCode 属性の値 (地域コード)、time 属性の値 (時間軸コード)、および VALUE 要素の内容 (系列の値。この例では人口総数) を取得します。
VALUE 要素 (XML断片) の例
<VALUE indicator="0201010000000010000" unit="090" stat="20020101" regionCode="01000" time="2010CY00" cycle="3" regionRank="3" isSeasonal="1" isProvisional="0">5506419</VALUE>
XMLFragmenter の主要パラメーター
XML Source:
XML Attribute: _response_body
Feature Paths Configuration:
Elements to Match: VALUE
Customize Attributes:
Flatten Options:
Enable Flattening: <checked>
Expose Attributes:
Attributes to Expose:
VALUE.regionCode (地域コード)
VALUE.time (時間軸コード)
VALUE (系列の値。この例では人口総数)
XML Attribute: _response_body
Feature Paths Configuration:
Elements to Match: VALUE
Customize Attributes:
Flatten Options:
Enable Flattening: <checked>
Expose Attributes:
Attributes to Expose:
VALUE.regionCode (地域コード)
VALUE.time (時間軸コード)
VALUE (系列の値。この例では人口総数)
XMLXQueryExploder: 地域の識別子 (コードと名称) を記述している CLASS 要素をXML断片として抽出します。統計ダッシュボードから取得したXML文書に含まれる CLASS 要素は、いくつかの CLASS_OBJ 要素の子要素としてグループ化されており、何を記述している CLASS 要素であるかは、親の CLASS_OBJ 要素の id 属性によって識別する仕組みになっています。ここでは、地域コードと地域名称を記述している CLASS 要素 (親要素の id 属性値が regionCode であるもの) のみを抽出したいので、断片化の対象とするXML要素の条件を XQuery 式によって自由に指定できる XMLXQueryExploder を使いました。
CLASS_OBJ 要素 (地域) と CLASS 要素の一部
<CLASS_OBJ id="regionCode" name="地域">
<CLASS code="01000" name="北海道"/>
<CLASS code="02000" name="青森県"/>
....
</CLASS_OBJ>
<CLASS code="01000" name="北海道"/>
<CLASS code="02000" name="青森県"/>
....
</CLASS_OBJ>
XMLXQueryExploder の主要パラメーター
XQuery Type:
XQuery Expression: //CLASS_OBJ[@id="regionCode"]/CLASS
XML Source:
XML Attribute: _response_body
Remove Source XML Attribute?: Yes
Results:
Result Attribute: _result
XQuery Expression: //CLASS_OBJ[@id="regionCode"]/CLASS
XML Source:
XML Attribute: _response_body
Remove Source XML Attribute?: Yes
Results:
Result Attribute: _result
XMLFlattener: XMLXQueryExploder によって抽出された各 CLASS 要素を平坦化して、code 属性の値 (地域コード) と name 属性の値 (地域名称。この例では都道府県名) を取得します。
XMLFlattener の主要パラメーター
XML Source:
XML Attribute: _result
Flatten Paths:
Elements to Match: CLASS
Expose Attributes:
Attributes to Expose:
CLASS.code (地域コード)
CLASS.name (地域名称)
XML Attribute: _result
Flatten Paths:
Elements to Match: CLASS
Expose Attributes:
Attributes to Expose:
CLASS.code (地域コード)
CLASS.name (地域名称)
最後に PostgreSQL ライターをワークスペースに追加、2つのフィーチャータイプ (population, region) で出力先テーブルのスキーマを定義し、XMLFragmenter, XMLFlattener トランスフォーマーと接続しました。
VALUE 要素の time 属性の値 (時間軸) は、単位が暦年の場合、"<西暦年>CY00" という書式のコードで記述されています。そのため、"population" ライターフィーチャータイプの User Attributes タブで、時間軸コードの先頭から4文字 (西暦年の部分) のみを year 列に書き込むように設定しました。
PostgreSQL ライター | population フィーチャータイプ (テーブル) の属性 (列) 定義

注: FME 2017.0 では、上の図のように、ライターフィーチャータイプ User Attributes タブ (Value 列) でも属性値を調製できるようになりました。
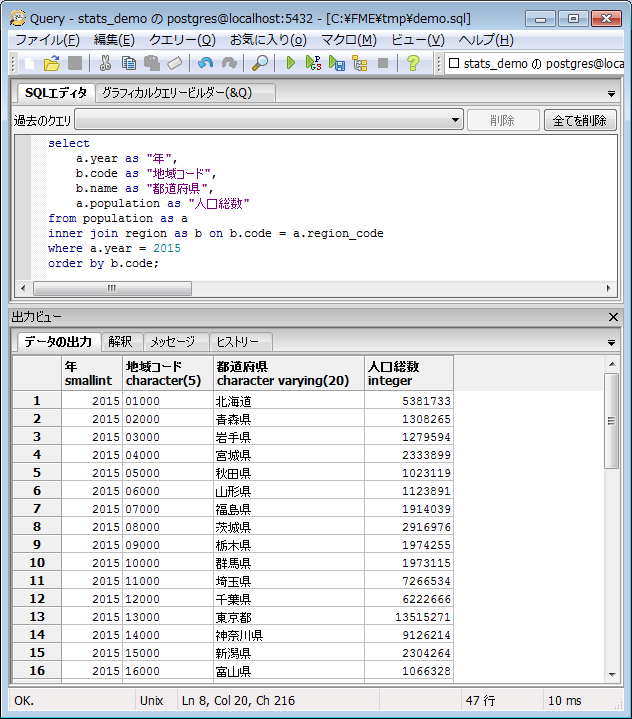
PostgreSQL データベースに対する SQL クエリ (問い合わせ) と結果テーブルの例:
2015年の都道府県別人口総数 (pgAdmin III クエリーツール)