今回は、このカスタムトランスフォーマーの基本的な使用方法を示すワークスペース例を掲げます。
FME Hub で公開されているカスタムトランスフォーマーは、通常のトランスフォーマーと同じ操作(Quick Add または Transformer Gallery からのドラッグ・アンド・ドロップ等)によって編集中のワークスペースに追加できます。ただし、ワークスペース編集に使用している FME Workbench のバージョンが当該カスタムトランスフォーマー作成時のバージョン以降であること、および、少なくとも初回はインターネットに接続していることが必要です。JpKsjVectorReader は FME 2017.0.1.1 で作成しました。
2017-08-02: FME Hub の JpKsjVecotorReader を更新しました。更新理由、内容については、本文後の「2017-08-02 更新について」で説明します。

Creator: 処理開始用のフィーチャーを1個作成、出力します。
JpKsjVectorReader: 次のようにパラメーターを設定することによって、国土数値情報「行政区域」データを読み込み、行政区域の範囲(面)を表すジオメトリと、その区域の主題属性を保持した "xml_fragment" 属性(地物クラスXML要素をルートとするXML断片)をもつフィーチャーを出力します。
- KSJ Vector Dataset (GML): <国土数値情報ダウンロードサービスサイトからダウンロードした「行政区域」データ解凍後の *.xml ファイルパス、または、解凍前の *.zip ファイルパス。複数可>
- Feature Types to Read: AdministrativeBoundary <「行政区域」データの「製品仕様書」で規定されている地物クラスのXML要素名>
JpKsjVectorReader パラメーター設定画面(行政区域)

国土数値情報の「製品仕様書」は、国土数値情報ダウンロードサービスサイトにおけるデータの種類別の説明ページ「データフォーマット(符号化)」の項で公開(PDF文書にリンク)されています。
XMLFlattener: "xml_fragment" 属性の値(地物クラスXML要素をルートとするXML断片)を平坦化して、個別の属性を抽出します。詳細は後述します。
Inspector: 変換終了後、全てのフィーチャーを FME Data Inspector で表示します。ベクタージオメトリの保存をサポートするデータフォーマットのライターをワークスペースに追加し、Inspector の代わりにライターのフィーチャータイプをここに接続すれば、そのフォーマットの「行政区域」データセットが作成できます。
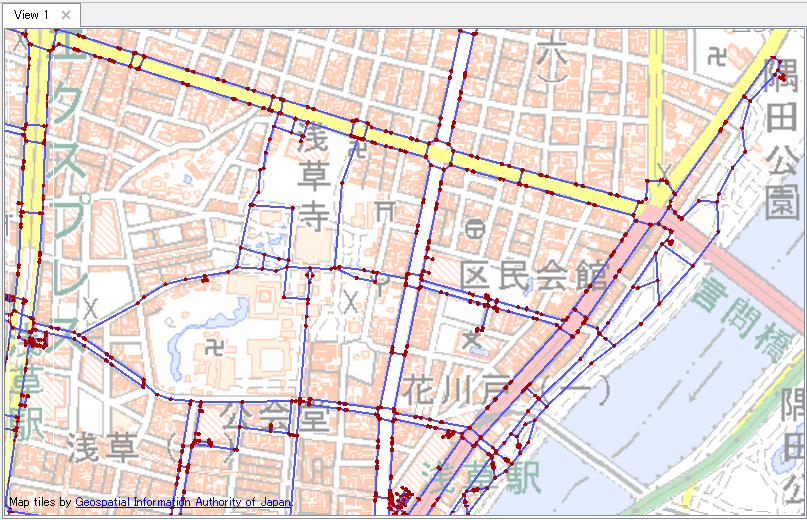
国土数値情報「行政区域」データ変換結果: 平成29年度, 四国4県(徳島県, 香川県, 愛媛県, 高知県)
FME Data Inspector による表示(背景: Esri ArcGIS Online Map Service - World Light Gray Base)。

XMLFlattener による属性の抽出
KsjVectorReader が出力するフィーチャーは、地物クラスのXML断片を "xml_fragment" 属性として持っているので、それを XMLFlattener によって平坦化することにより、下位のXML要素/属性に記述されている内容をフィーチャーの属性として抽出することができます。XMLの断片化 (fragmentation)、平坦化 (flattening) については「XMLの読込 - 断片化と平坦化」もご参照ください。
国土数値情報「行政区域」AdministrativeBoundary クラスXML要素(XML断片)の例
<?xml version="1.0" encoding="UTF-8"?>
<ksj:AdministrativeBoundary xmlns:ksj="http://nlftp.mlit.go.jp/ksj/schemas/ksj-app" xmlns:gml="http://www.opengis.net/gml/3.2" gml:id="gy0">
<ksj:bounds xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#sf0"/>
<ksj:prefectureName>愛媛県</ksj:prefectureName>
<ksj:subPrefectureName/>
<ksj:countyName/>
<ksj:cityName>松山市</ksj:cityName>
<ksj:administrativeAreaCode codeSpace="AdministrativeAreaCode.xml">38201</ksj:administrativeAreaCode>
</ksj:AdministrativeBoundary>
<ksj:AdministrativeBoundary xmlns:ksj="http://nlftp.mlit.go.jp/ksj/schemas/ksj-app" xmlns:gml="http://www.opengis.net/gml/3.2" gml:id="gy0">
<ksj:bounds xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#sf0"/>
<ksj:prefectureName>愛媛県</ksj:prefectureName>
<ksj:subPrefectureName/>
<ksj:countyName/>
<ksj:cityName>松山市</ksj:cityName>
<ksj:administrativeAreaCode codeSpace="AdministrativeAreaCode.xml">38201</ksj:administrativeAreaCode>
</ksj:AdministrativeBoundary>
このXML断片を平坦化すると、次の表に掲げる属性が抽出されます。
国土数値情報「行政区域」フィーチャーの属性
参考: 国土数値情報(行政区域)製品仕様書 第 2.3 版(平成28年3月 国土交通省国土政策局)
| 属性名 | 内容 | 備考 |
|---|---|---|
| AdministrativeBoundary.id | フィーチャーID | //ksj:AdministrativeBoundary/@gml:id |
| bounds.href | 範囲(面)を表すジオメトリのID | 参照先の //gml:Surface/@gml:id |
| prefectureName | 都道府県名 | |
| subPrefectureName | 支庁・振興局名 | 北海道の支庁・振興局の名称 |
| countyName | 郡・政令都市名 | |
| cityName | 市区町村名 | |
| administrativeAreaCode | 行政区域コード | JIS X 0401, JIS X 0402 |
- formationDate.TimeInstant.timePosition (成立年月日)
- disappearanceDate.TimeInstant.timePosition (消滅年月日)
上記のような平坦化を行うための XMLFlattener のパラメーター設定は、次のとおりです。
- XML Source Type: Attribute with XML document
- XML Attribute: xml_fragment
- Elements to Match: AdministrativeBoundary
- Attributes to Expose: <平坦化によって抽出される属性のうち、Workbench のインターフェース上に現す必要があるものの名前。上の表の全ての属性名を現す必要はなく、後続のトランスフォーマー等で利用したい属性だけで構いません>
XMLFlattener パラメーター設定画面

FMEワークスペース例2: 国土数値情報「河川」データ読込 (FME 2017.0.1.1 build 17291)

JpKsjVectorReader: 国土数値情報「河川」データでは、1つのデータセット(ファイル)に2つの地物クラス: Stream (流路) と RiverNode (河川端点) のデータが記述されています。どちらも同時に読み込む場合には、JpKsjVectorReader の Feature Types to Read パラメーターに、空白類文字(半角スパース、タブ、または改行)区切りでそれらを列挙します。
JpKsjVectorReader パラメーター設定画面(河川)

FeatureTypeFilter: 地物クラス名(Stream, RiverNode) はフィーチャータイプ名("fme_feature_type" 属性の値)として扱われるので、JpKsjVectorReader が出力するフィーチャーは、FeatureTypeFilter によって地物クラス(フィーチャータイプ)別のデータフローに振り分けることができます。
XMLFlattener: その後、前述の行政区域と同様に XMLFlattener で属性を抽出します。
国土数値情報「河川」データ変換結果: 四国4県(徳島県, 香川県, 愛媛県, 高知県)流路のみ表示
FME Data Inspector による表示(背景: Esri ArgGIS Online Map Service - World Light Gray Base)。

XMLFlattener による属性の抽出方法は、行政区域の場合と同じです。以下、Stream, RiverNode クラスのXML断片(例)と、それを平坦化することによって得られる属性の一覧表を掲げます。
国土数値情報「河川」 Stream (流路) クラスXML要素(XML断片)の例
<?xml version="1.0" encoding="UTF-8"?>
<ksj:Stream xmlns:ksj="http://nlftp.mlit.go.jp/ksj/schemas/ksj-app" xmlns:gml="http://www.opengis.net/gml/3.2" gml:id="r-3700001">
<ksj:waterSystemCode codeSpace="WaterSystemTypeCode.xml">880807</ksj:waterSystemCode>
<ksj:location xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#c-3700001"/>
<ksj:riverCode codeSpace="RiverTypeCode.xml">8808070000</ksj:riverCode>
<ksj:sectionType>0</ksj:sectionType>
<ksj:riverName>宮川</ksj:riverName>
<ksj:originalDataType>2</ksj:originalDataType>
<ksj:flowDirection>1</ksj:flowDirection>
<ksj:startRiverNode xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#t-3701506"/>
<ksj:endRiverNode xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#t-3701551"/>
<ksj:startStreamNode xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#t-3701506"/>
<ksj:endStreamNode xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#t-3701504"/>
</ksj:Stream>
<ksj:Stream xmlns:ksj="http://nlftp.mlit.go.jp/ksj/schemas/ksj-app" xmlns:gml="http://www.opengis.net/gml/3.2" gml:id="r-3700001">
<ksj:waterSystemCode codeSpace="WaterSystemTypeCode.xml">880807</ksj:waterSystemCode>
<ksj:location xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#c-3700001"/>
<ksj:riverCode codeSpace="RiverTypeCode.xml">8808070000</ksj:riverCode>
<ksj:sectionType>0</ksj:sectionType>
<ksj:riverName>宮川</ksj:riverName>
<ksj:originalDataType>2</ksj:originalDataType>
<ksj:flowDirection>1</ksj:flowDirection>
<ksj:startRiverNode xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#t-3701506"/>
<ksj:endRiverNode xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#t-3701551"/>
<ksj:startStreamNode xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#t-3701506"/>
<ksj:endStreamNode xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#t-3701504"/>
</ksj:Stream>
国土数値情報「河川」 Stream (流路) フィーチャーの属性
参考: 国土数値情報(河川)製品仕様書 第 3.1 版(平成24年3月 国土交通省国土政策局)
| 属性名 | 内容 | 備考 |
|---|---|---|
| Stream.id | フィーチャーID | //ksj:Stream/@gml:id |
| waterSystemCode | 水系域コード | |
| location.href | 場所(線)を表すジオメトリのID | 参照先の //gml:Curve/@gml:id |
| riverCode | 河川コード | |
| sectionType | 区間種別コード | |
| riverName | 河川名 | |
| originalDataType | 原点資料種別コード | |
| flowDirection | 流下方向判定 | |
| startRiverNode.href | 河川始点 | 河川の始点に該当する河川端点フィーチャーのID |
| endRiverNode.href | 河川終点 | 河川の終点に該当する河川端点フィーチャーのID |
| startStreamNode.href | 流路始点 | 流路の始点に該当する河川端点フィーチャーのID |
| endStreamNode.href | 流路終点 | 流路の終点に該当する河川端点フィーチャーのID |
国土数値情報「河川」 RiverNode (河川端点) クラスXML要素(XML断片)の例
<?xml version="1.0" encoding="UTF-8"?>
<ksj:RiverNode xmlns:ksj="http://nlftp.mlit.go.jp/ksj/schemas/ksj-app" xmlns:gml="http://www.opengis.net/gml/3.2" gml:id="t-3601133">
<ksj:waterSystemCode codeSpace="WaterSystemTypeCode.xml">880807</ksj:waterSystemCode>
<ksj:position xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#p-3601133"/>
<ksj:elevation>289</ksj:elevation>
</ksj:RiverNode>
<ksj:RiverNode xmlns:ksj="http://nlftp.mlit.go.jp/ksj/schemas/ksj-app" xmlns:gml="http://www.opengis.net/gml/3.2" gml:id="t-3601133">
<ksj:waterSystemCode codeSpace="WaterSystemTypeCode.xml">880807</ksj:waterSystemCode>
<ksj:position xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#p-3601133"/>
<ksj:elevation>289</ksj:elevation>
</ksj:RiverNode>
国土数値情報「河川」 RiverNode (河川端点) フィーチャーの属性
参考: 国土数値情報(河川)製品仕様書 第 3.1 版(平成24年3月 国土交通省国土政策局)
| 属性名 | 内容 | 備考 |
|---|---|---|
| RiverNode.id | フィーチャーID | //ksj:RiverNode/@gml:id |
| waterSystemCode | 水系域コード | |
| position.href | 地点を表すジオメトリのID | 参照先の //gml:Point/@gml:id |
| elevation | 標高 |
地物クラスのXML要素名(フィーチャータイプ名)やその下位のXML要素/属性名は「製品仕様書」で規定されていますが、階層構造を持っている属性については全ての子孫要素名や構造が分からない場合があり、また、あってはならないことなのですが、現実には「製品仕様書」で規定されている符号化規則と実際のデータの記述形式が矛盾している場合もあります。
そのため、 JpKsjVectorReader や XMLFlattener のパラメーターの設定にあたっては、「製品仕様書」を調べるだけでなく、データ本体をテキストエディタで開く等により、実際のデータに記述されているXML要素/属性名や階層構造も確認することをお勧めします。
「製品仕様書」とデータの記述形式の間の矛盾に関しては、データの不具合と思われるケースと「製品仕様書」の誤記と思われるケースの両方がありますが、FMEはデータしか読みませんので、前者(データの不具合)であったとしても、データが修正されない限りは、データの記述形式の方に合わせてワークスペースを構成する必要があります。
ただし、以下に掲げるデータ不具合の修復については、JpKsjVectorReader が自動的に行います。
- gml:Point 要素下位の gml:position は gml:pos とみなす(GMLスキーマでは、座標を記述するXML要素名は "gml:pos" が正)。
- gml:OrientableCurve/gml:baseCurve/@xlink:href の値と一致するIDをもつ gml:Curve 要素が見つからなかった場合、サフィクス _* を削除したIDによってリトライする。
2017-08-02 更新について
国土数値情報(GML形式)のXML文書では、ジオメトリを記述するGML要素(gml:Point, gml:Curve, gml:Surface) と地物クラスXML要素 (例えば、行政区域であれば ksj:AdministrativeBoundary) は同一の階層レベルで記述されており、地物クラスXML要素に属する特定の子要素の xlink:href 属性によって、地物のジオメトリを表すGML要素を参照する仕組みとなっています。
例えば、次の行政区域XML要素は、bounds 要素 xlink:href 属性の値 "#sf0" によって、同一文書内の他の場所に記述されている特定の gml:Surface 要素を参照し、そのジオメトリと結合することができます。
<?xml version="1.0" encoding="UTF-8"?>
<ksj:AdministrativeBoundary xmlns:ksj="http://nlftp.mlit.go.jp/ksj/schemas/ksj-app" xmlns:gml="http://www.opengis.net/gml/3.2" gml:id="gy0">
<ksj:bounds xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#sf0"/>
<ksj:prefectureName>愛媛県</ksj:prefectureName>
<ksj:subPrefectureName/>
<ksj:countyName/>
<ksj:cityName>松山市</ksj:cityName>
<ksj:administrativeAreaCode codeSpace="AdministrativeAreaCode.xml">38201</ksj:administrativeAreaCode>
</ksj:AdministrativeBoundary>
<ksj:AdministrativeBoundary xmlns:ksj="http://nlftp.mlit.go.jp/ksj/schemas/ksj-app" xmlns:gml="http://www.opengis.net/gml/3.2" gml:id="gy0">
<ksj:bounds xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#sf0"/>
<ksj:prefectureName>愛媛県</ksj:prefectureName>
<ksj:subPrefectureName/>
<ksj:countyName/>
<ksj:cityName>松山市</ksj:cityName>
<ksj:administrativeAreaCode codeSpace="AdministrativeAreaCode.xml">38201</ksj:administrativeAreaCode>
</ksj:AdministrativeBoundary>
国土数値情報では、GML形式のデータの公開開始以来、多くのデータで、xlink:href 属性によってGML要素を参照するためのXML要素の名前として
- position (gml:Point を参照)
- location (gml:Curve を参照)
- bounds (gml:Surface を参照)
そのため、当初の JpKsjVectorReader では、上記3種の要素名 + 既知の例外 are (gml:Surface を参照) のみをサポートし、もしその他の例外があった場合には、発見した時点で拡充していく方針としていました。
しかし、近年のデータをいくつか調べたところ、例外的な要素名が予想以上の頻度で見つかりました(例: 都市公園データでは loc で gml:Point を参照、バスルートデータでは brt で gml:Curve を参照)。最近は、場当たり的にジオメトリ参照用のXML要素名が決定されているように見受けられます。
ジオメトリ参照用のXML要素名としてどんな名前が現れるか予測不能であるだけでなく、例外的な名前が現れる頻度も高いと思われることから、発見した時点で拡充していくという方針を改め、今回の更新によって、ワークスペースの作成者が、読み込もうとするデータで実際に使われているジオメトリ参照用のXML要素の名前を指定できるよう、以下のパラメーターを追加しました。
| パラメーター名 | 設定内容 | 初期設定値 |
|---|---|---|
| Elements to Refer Point | 点ジオメトリ参照用のXML要素の名前 | position |
| Elements to Refer Curve | 線ジオメトリ参照用のXML要素の名前 | location |
| Elements to Refer Surface | 面ジオメトリ参照用のXML要素の名前 | bounds |
ジオメトリ参照用のXML要素名は、データの種類別に「製品仕様書」(符号化規則)で規定されています。また、データ本体(XML文書)をテキストエディタ等で開き、内容を直接確認することもできます。
例えば、点ジオメトリ参照用のXML要素名が loc であるデータを読み込む場合は、Elements to Refer Point パラメーターに loc を設定してください。
これらのパラメーターには、空白類文字(半角スペース、タブ、改行)で区切ることにより、それぞれ複数のXML要素名を同時に指定することもできます。例えば、複数の異なる種類のデータを連続して読み込む場合で、ジオメトリ参照用のXML要素の標準的な名前(初期設定値: position, location, bounds)と既知の例外的な名前(loc, brt, are)が全て現れるのであれば、次の図ように設定します。

また、これらのパラメーターのうち、読み込もうとするデータ内には存在しないことが明らかなジオメトリの種類(点、線、または面)に対応するものの設定は省略できます。ただし、これらの3パラメーターの設定を全て省略した場合は、このトランスフォーマーはデータを読み込まず、入力フィーチャーを <Rejected> ポートから出力します。